Random thoughts
Tuesday, January 31, 2012
Google Browser Size: Is your content visible?
Have you ever wondered how much of your carefully designed Web page is actually visible to the people coming to your site?
Then take a look at Google Browser Size, an amazingly simple and effective tool for Web designers to see what percentage of users sees which content, like this:

Of course we all know to place important content towards the top, above the fold, we have seen the heatmaps from eye tracking studies, and we all test at different screen sizes, right? Google Browser Size, already launched back in December 2009, just makes the testing easier and
The visualization is based on browser window sizes of people who visit Google, not on actual browser window sizes used when accessing a particular site. Depending on how closely your audience matches the average Google visitor, results may vary.
One caveat: As mentioned on the Browser Size website, the tool works best on web pages with a fixed layout aligned to the left. The visualization can be misleading for liquid or reactive pages that adjust to the available screen width, we well as centered pages.
Then take a look at Google Browser Size, an amazingly simple and effective tool for Web designers to see what percentage of users sees which content, like this:
Of course we all know to place important content towards the top, above the fold, we have seen the heatmaps from eye tracking studies, and we all test at different screen sizes, right? Google Browser Size, already launched back in December 2009, just makes the testing easier and
brings this home with shocking immediacy(Mike Moran at Biznology).
The visualization is based on browser window sizes of people who visit Google, not on actual browser window sizes used when accessing a particular site. Depending on how closely your audience matches the average Google visitor, results may vary.
One caveat: As mentioned on the Browser Size website, the tool works best on web pages with a fixed layout aligned to the left. The visualization can be misleading for liquid or reactive pages that adjust to the available screen width, we well as centered pages.
Labels: google, seo, usability, webdevelopment
Monday, October 24, 2011
Google encrypting searches: security, privacy and control

Google recently announced plans to make search more secure.
This effort includes encrypting search queries, which is especially important when using an unsecured Internet connection or accessing the Internet through intermediate devices which have the ability to log requests. Encrypting the search interface will automatically block referrer information for unencrypted sites, and would provide an incentive for companies to join the industry effort to use SSL/TLS encryption more widely.
But Google takes this a step further, hiding query information from encrypted searches. The click-through tracking link for unencrypted search includes the search term parameter “q”, which gets passed to the visited website:
http://www.google.com/url?sa=t&rct=j&q=&esrc=s&frm=1&url=http%3A%2F%2Fexample.com%2F
The link for encrypted search, however, leaves the parameter “q” empty. Interestingly click-throughs for encrypted searches are tracked on an unencrypted connection, thus revealing the visited site address to an eavesdropper:
http://www.google.com/url?sa=t&rct=j&q=example&url=http%3A%2F%2Fexample.com%2F
With this change, the visited website receives no information about the search term. What enhances privacy for searchers holds website owners off important information for optimizing their websites to best serve visitors.
Browsers already provide mechanisms for controlling referrer information, for example the network.http.sendRefererHeader preference setting or the customizable RefControl extension for Firefox. Google’s privacy enhancement takes control away from the users by not passing referring information, period.
Google’s move has the potential to change the search engine marketing (SEM) landscape. Search terms in paid ads will remain trackable unchanged. For organic search, the only way for website owners to get access to, albeit delayed, aggregated and limited to the top 1,000, search terms is through Google webmaster console, a very fine tool but not a replacement for an integrated web analytics solution.
The impact of this change goes beyond web analytics and search engine optimization (SEO): Sites often use the search terms that led visitors to the site for dynamic customization, offering related information and links. With encrypted search, visitors will no longer have access to these enhancements either.
Wednesday, February 9, 2011
Google vs. Bing: A technical solution for fair use of clickstream data
 When Google engineers noticed that Bing unexpectedly returned the same result as Google for a misspelling of tarsorrhapy, they concluded that somehow Bing considered Google’s search results for its own ranking. Danny Sullivan ran the story about Bing cheating and copying Google search results last week. (Also read his second article on this subject, Bing: Why Google’s Wrong In Its Accusations.)
When Google engineers noticed that Bing unexpectedly returned the same result as Google for a misspelling of tarsorrhapy, they concluded that somehow Bing considered Google’s search results for its own ranking. Danny Sullivan ran the story about Bing cheating and copying Google search results last week. (Also read his second article on this subject, Bing: Why Google’s Wrong In Its Accusations.)Google decided to create a trap for Bing by returning results for about 100 bogus terms, as Amit Singhal, a Google Fellow who oversees the search engine’s ranking algorithm, explains:
To be clear, the synthetic query had no relationship with the inserted result we chose—the query didn’t appear on the webpage, and there were no links to the webpage with that query phrase. In other words, there was absolutely no reason for any search engine to return that webpage for that synthetic query. You can think of the synthetic queries with inserted results as the search engine equivalent of marked bills in a bank.Running Internet Explorer 8 with the Bing toolbar installed, and the “Suggested Sites” feature of IE8 enabled, Google engineers searched Google for these terms and clicked on the inserted results, and confirmed that a few of these results, including “delhipublicschool40 chdjob”, “hiybbprqag”, “indoswiftjobinproduction”, “jiudgefallon”, “juegosdeben1ogrande”, “mbzrxpgjys” and “ygyuuttuu hjhhiihhhu”, started appearing in Bing a few weeks later:

The experiment showed that Bing uses clickstream data to determine relevant content, a fact that Microsoft’s Harry Shum, Vice President Bing, confirmed:
We use over 1,000 different signals and features in our ranking algorithm. A small piece of that is clickstream data we get from some of our customers, who opt-in to sharing anonymous data as they navigate the web in order to help us improve the experience for all users.These clickstream data include Google search results, more specifically the click-throughs from Google search result pages. Bing considers these for its own results and consequently may show pages which otherwise wouldn’t show in the results at all since they don’t contain the search term, or rank results differently. Relying on a single signal made Bing susceptible to spamming, and algorithms would need to be improved to weed suspicious results out, Shum acknowledged.
As an aside, Google had also experienced in the past how relying too heavily on a few signals allowed individuals to influence the ranking of particular pages for search terms such as “miserable failure”; despite improvements to the ranking algorithm we continue to see successful Google bombs. (John Dozier's book about Google bombing nicely explains how to protect yourself from online defamation.)
The experiment failed to validate if other sources are considered in the clickstream data. Outraged about the findings, Google accused Bing of stealing its data and claimed that “Bing results increasingly look like an incomplete, stale version of Google results—a cheap imitation”.
Whither clickstream data?
Privacy concerns aside—customers installing IE8 and the Bing toolbar, or most other toolbars for that matter, may not fully understand and often not care how their behavior is tracked and shared with vendors—using clickstream data to determine relevant content for search results makes sense. Search engines have long considered click-throughs on their results pages in ranking algorithms, and specialized search engines or site search functions will often expose content that a general purpose search engine crawler hasn’t found yet.Google also collects loads of clickstream data from the Google toolbar and the popular Google Analytics service, but claims that Google does not consider Google Analytics for page ranking.
Using clickstream data from browsers and toolbars to discover additional pages and seeding the crawler with those pages is different from using the referring information to determine relevant results for search terms. Microsoft Research recently published a paper Learning Phrase-Based Spelling Error Models from Clickthrough Data about how to improve the spelling corrections by using click data from “other search engines”. While there is no evidence that the described techniques have been implemented in Bing, “targeting Google deliberately” as Matt Cutts puts it would undoubtedly go beyond fair use of clickstream data.
Google considers the use of clickstream data that contains Google Search URLs plagiarism and doesn't want another search engine to use this data. With Google dominating the search market and handling the vast majority of searches, Bing's inclusion of results from a competitor remains questionable even without targeting, and dropping that signal from the algorithm would be a wise choice.
Should all clickstream data be dropped from the ranking algorithms, or just certain sources? Will the courts decide what constitutes fair use of clickstream data and who “owns” these data, or can we come up with a technical solution?
Robots Exclusion Protocol to the rescue
The Robots Exclusion Protocol provides an effective and scalable mechanism for selecting appropriate sources for resource discovery and ranking. Clickstream data sources and crawlers results have a lot in common. Both provide information about pages for inclusion in the search index, and relevance information in the form of inbound links or referring pages, respectively.| Dimension | Crawler | Clickstream |
|---|---|---|
| Source | Web page | Referring page |
| Target | Link | Followed link |
| Weight | Link count and equity | Click volume |
Following the Robots Exclusion Protocol, search engines only index Web pages which are not blocked in robots.txt, and not marked non-indexable with a robots meta tag. Applying the protocol to clickstream data, search engines should only consider indexable pages in the ranking algorithms, and limit the use of clickstream data to resource discovery when the referring page cannot be indexed.
Search engines will still be able to use clickstream data from sites which allow access to local search results, for example the site search on amazon.com, whereas Google search results are marked as non-indexable in http://www.google.com/robots.txt and therefore excluded.
Clear disclosure how clickstream data are used and a choice to opt-in or opt-out put Web users in control of their clickstream data. Applying the Robots Exclusion Protocol to clickstream data will further allow Web site owners to control third party use of their URL information.
Labels: bing, google, microsoft, seo, technology, webdevelopment
Tuesday, August 11, 2009
Security, privacy, and an inconvenience
Redirects are often discussed only in the context of search engine optimization (SEO). Here is a good example how redirects affect users as well, and why it is important to choose your redirects wisely.
The Central Intelligence Agency (CIA) in 2006 began serving its Website encrypted in an effort to improve security and privacy of the communication.
This is a clear case for a 301 redirect from the unencrypted URL http://www.cia.gov/page to the equivalent encrypted URL https://www.cia.gov/page. Instead, except for the homepage and very few other pages, all requests get redirected to a splash page informing visitors about the site changes:
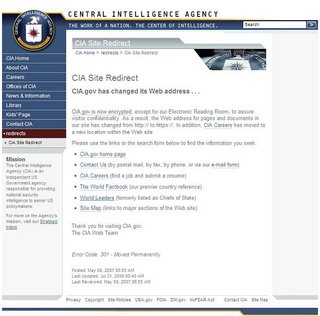
Not only is this a bad idea for search since all those links out there on various sites now transfer link weight to a splash page which is marked as non-indexable. It is also an inconvenience to users who need to navigate to the specific content or go back to the previous page and try again with an edited link.
Even the old URL for the World Factbook, arguably one of the most popular resources on the site, no longer goes to the desired World Factbook homepage directly.
The CIA press release states: “We believe the inconveniences of implementing SSL for the entire website will be offset by increased visitor confidence that they are, in fact, connected to the CIA website and that their visits are secure and confidential.”
The effort to increased security and privacy is commendable, and encrypting all communication with the agency certainly isn't a bad idea. Doing so without the inconveniences would be even better though, and perfectly feasible, too.
The Central Intelligence Agency (CIA) in 2006 began serving its Website encrypted in an effort to improve security and privacy of the communication.
This is a clear case for a 301 redirect from the unencrypted URL http://www.cia.gov/page to the equivalent encrypted URL https://www.cia.gov/page. Instead, except for the homepage and very few other pages, all requests get redirected to a splash page informing visitors about the site changes:
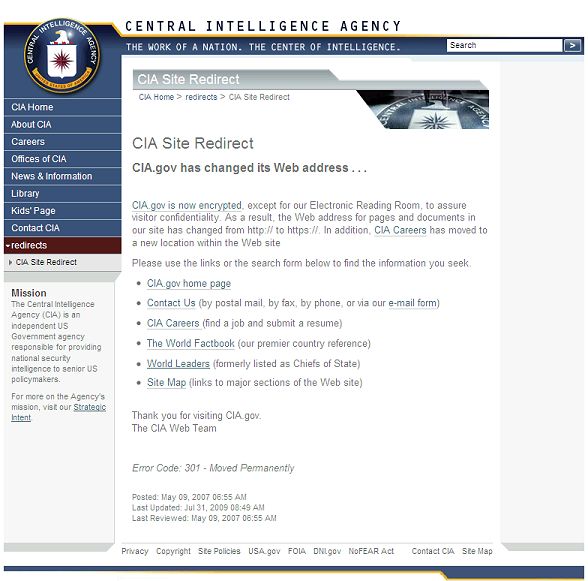
Not only is this a bad idea for search since all those links out there on various sites now transfer link weight to a splash page which is marked as non-indexable. It is also an inconvenience to users who need to navigate to the specific content or go back to the previous page and try again with an edited link.
Even the old URL for the World Factbook, arguably one of the most popular resources on the site, no longer goes to the desired World Factbook homepage directly.
The CIA press release states: “We believe the inconveniences of implementing SSL for the entire website will be offset by increased visitor confidence that they are, in fact, connected to the CIA website and that their visits are secure and confidential.”
The effort to increased security and privacy is commendable, and encrypting all communication with the agency certainly isn't a bad idea. Doing so without the inconveniences would be even better though, and perfectly feasible, too.
Labels: networking, seo, technology
Monday, August 10, 2009
SEO advice: Redirect wisely
More often than not you will see someone recommend switching all redirects on your site to 301s because they pass “link equity” in Google. There is the simple and neat solution for search engine optimization, and it could be plain wrong. At the risk of diverging from the consensus in your favorite discussion forum or offending your SEO consultant, read on and decide for yourself.
Redirects instruct browsers and search engine crawlers that content is available under a different URL. They often go unnoticed as we access Websites. Along with the new location of the content, the server also sends a response code indicating the type of redirect. From an SEO perspective, you generally care about two response codes, 301 Moved permanently and 302 Found:
Let's summarize the effects of the two most common redirect status codes again:
The 301 redirect response is appropriate for the following scenarios:
When Google introduced the “canonical” meta tag in February 2009, this suddenly made sense. Once multiple URLs are known to refer to the same page, or a slight variation of a page, the index only needs to keep one instance of the page.
The canonical meta tag helps the webmaster of a site who give search engines a hint about the preferred URL. The canonical meta tag also helps search engines since mapping multiple crawled URLs to the same page and indexing it only once just became easier.
Whether link equity fully transfers between multiple URLs mapped to the same page remains to be seen. At least within the same domain, this unification process may allow keeping the vanity URL in the index with a 302 redirect response while still transferring link equity.
PS. For an excellent and detailed description how redirects work, how to configure your Web server and what each status code does, see Sebstian's pamphlet The anatomy of a server sided redirect: 301, 302 and 307 illuminated SEO wise.
Redirects instruct browsers and search engine crawlers that content is available under a different URL. They often go unnoticed as we access Websites. Along with the new location of the content, the server also sends a response code indicating the type of redirect. From an SEO perspective, you generally care about two response codes, 301 Moved permanently and 302 Found:
- 301 Moved permanently indicates that the resource has been assigned a different URL permanently, and the original URL should no longer be used. What this means for Search engines is that should index the new URL only. Google also transfers full link equity with a 301 redirect, which is the very reason why you will often see the advice to use 301 redirects.
- 302 Found indicates that the originally requested URL is still valid, and should continue to be used. Search engines vary in how they treat 302 redirects and which URL they show in search result pages, but generally will continue to crawl the original URL as recommended in the HTTP/1.1 specification: “The requested resource resides temporarily under a different URI. Since the redirection might be altered on occasion, the client SHOULD continue to use the Request-URI for future requests.”
Choosing the right redirect response code
So which redirect response code should you use? Matt Cutts' description how Google treats on-domain and off-domain 302 redirects covers the basic principles and the heuristics that Google used at the time, which to a large extent still apply.Let's summarize the effects of the two most common redirect status codes again:
- 301 redirects transfer link equity to the new URL.
- 301 redirects remove the original URL from the search index.
- 302 redirects often keep the original URL in the index.
The 301 redirect response is appropriate for the following scenarios:
- Content has moved to a different location permanently, for example to a different server name or a different directory structure of the same server. This may be triggered by the rebranding of content where you want all references to the original content to disappear.
- A Website is accessible under multiple host names, such as example.com and www.example.com, or typo catchers like eggsample.com and example.org, but only one name should be indexed.
- A temporary campaign URL is published in direct mail or print advertising, but the landing page has a different permanent URL that will remain accessible beyond the lifetime of the campaign.
- The requested URL does not match the canonical URL for the resource. Often extraneous session and tracking parameters can be stripped, or path information gets added to help with search rankings, for example http://www.amazon.com/Software-
Development- Principles- Patterns- Practices/dp/0135974445
- The original URL is shorter, prettier, more meaningful, etc. and therefore should show on the search engine results page.
- Temporary session or tracking information gets added to the canonical URL. Those URL parameters should not be indexed since they will not apply to other visitors.
- Multiple load balanced servers deliver the content. Indexing an individual server would defeat the purpose of using load balancing. (There are better ways to load balance than having multiple server names, though.)
The “canonical” meta tag
How can you keep the short URL in the index and still transfer link equity? In summer 2008, we started observing that Google somehow “merged” related URLs and treated them as a single entity, showing identical page rank and identical number of inbound links to all of the URLs.When Google introduced the “canonical” meta tag in February 2009, this suddenly made sense. Once multiple URLs are known to refer to the same page, or a slight variation of a page, the index only needs to keep one instance of the page.
The canonical meta tag helps the webmaster of a site who give search engines a hint about the preferred URL. The canonical meta tag also helps search engines since mapping multiple crawled URLs to the same page and indexing it only once just became easier.
Whether link equity fully transfers between multiple URLs mapped to the same page remains to be seen. At least within the same domain, this unification process may allow keeping the vanity URL in the index with a 302 redirect response while still transferring link equity.
PS. For an excellent and detailed description how redirects work, how to configure your Web server and what each status code does, see Sebstian's pamphlet The anatomy of a server sided redirect: 301, 302 and 307 illuminated SEO wise.
Labels: networking, seo, webdevelopment