Random thoughts
Friday, May 24, 2019
Happy birthday, www.ibm.com!

Happy birthday, www.ibm.com, and welcome to the Quarter Century Club!
Related links:
- IBM
- IBM homepage history in screenshots by IBM's first corporate webmaster, Ed Costello
Labels: ibm, technology, webdevelopment
Thursday, May 17, 2018
WeAreDevelopers 2018 conference notes – Day 2






Related links
Labels: austria, technology, wearedevs, webdevelopment
Wednesday, May 16, 2018
WeAreDevelopers 2018 conference notes – Day 1
Registration was surprisingly fast and painless, a Graham roll and an energy drink as developer breakfast maybe slightly too clichéic (or I am getting old), but fortunately there was plenty of coffee available all day, including decent cappuccino at one of the sponsor booths.
Asked at the conference opening what topics people would be most interested in hearing about, Blockchain came out first, followed by machine learning and, still, devops.

Steve Wozniak rocked the Austria Center with an inspiring “fireside chat”. Talking with the brilliant Monty Munford, The Woz answered questions submitted by the audience and shared his views on anything from the early days of computing and why being a developer was great then (“Developers can do things that other people can’t.”) to self-driving electric cars (overselling and underdelivering) and the Blockchain (too early, similar to the dot com bubble), interspersed with personal anecdotes and, as a running gag, promoting the Apple iCloud.

As a long-time mainframe guy, I liked his claimed his programming language skills too, FORTRAN, COBOL, PL/I, and IBM System/360 assembler, although he did mention playing more with the Raspberry Pi these days.
Mobile payments was a good example of the design principles that made Apple famous and successful. Steve mentioned how painful early mobile payment solutions were, requiring multiple manual steps to initiate and eventually sign off a transaction, compared to Apple Pay where you don’t even need to unlock your device (I haven’t tried either one, and they don’t seem to be too popular yet.)
The most valuable advice though was to do what you are good at and what you like (“money is secondary”), to keep things simple, and live your life instead of showing it off, which is why he left Facebook, feeling that he didn’t get enough back in return. For an absolutely brilliant graphical summary of the session, see Katja Budnikov’s real-time sketch note.
Johannes Pichler of karriere.at followed an ambitious plan to explain OAuth 2.0 from the protocol to to a sample PHP implementation in just 45 minutes. I may need to take another look at the presentation deck later to work through the gory details.
A quick deployment option is to use one of the popular shared services such as oauth.io or auth0.com, but it comes at the price of completely outsourcing authentication and authorization and having to transfer user data to the cloud. For the development of an OAuth server, several frameworks are available including node.oauth2 server for NodeJS, Sprint Security OAuth2 for Java, and the Slim framework for PHP.
In the afternoon, Jan Mendling of the WU Executive Academy looked at how disruptive technologies like Blockchain, Robotic Process Automation, and Process Mining shape business processes of the future. One interesting observation is about product innovation versus process innovation: most disruptive companies like Uber or Foodora still offer the same products, like getting you from A to B, serving food, etc. but with different processes.
Tasks can be further classified as routine versus non-routine, and cognitive versus manual. Traditionally, computerization has focused on routine, repetitive cognitive tasks only. Increasingly we are seeing computers also take on non-routine cognitive tasks (for example, Watson interpreting medical images), and routine manual, physical tasks (for example, Amazon warehouse automation).
Creating Enterprise Web Applications with Node.js was so popular that security did not let more people in, and there was no overflow area available either, so I missed this one and will have to go with the presentation only.
Equally crowded was Jeremiah Lee’s session JSON API: Your smart default. Talking about his experience at Fitbit with huge data volumes and evolving data needs, he made the case why jsonapi.org should be the default style for most applications, making use of HTTP caching features and enabling “right-sized” APIs.

Hitting on GraphQL, Jeremiah made the point that developer experience is not more important than end user performance. That said, small resources and lots of HTTP request s should be okay now. The debate between response size vs number of requests is partially resolved by improvements of the network communication, namely HTTP/2 header compression and pipelining, reduced latency with TLS 1.3 and faster and more resilient LTE mobile networks, and by mechanisms to selectively include data on demand using the include and fields attributes.
Data model normalization and keeping the data model between the clients and the server consistent was another important point, and the basis for efficient synchronizatiion and caching. There is even a JSON Patch format for selectively changing JSON documents.
Niklas Heidoff of IBM compared Serverless and Kubernetes and recommended to always use Istio with Kubernetes deployments. There is not a single approach for Serverless. The focus of this talk was on Apache OpenWhisk.

Kubernetes was originally used at Google internally, therefore it is considered pretty mature already despite being open source for only a short time. Minikube or Docker can be used to run Kubernetes locally. Composer is a programming model for orchestrating OpenWhisk functions.
Niklas went on to show a demo how to use Istio for versioning and a/b testing. This cannot be done easily with Serverless, which is mostly concerned about simplicity, just offering (unversioned) functions.
The workshop on Interledger and Website monetization gave an overview of the Interledger architecture, introducing layers for sending transactions very much like TCP/IP layers are used for sending packets over a network. Unlike Lightning, which is source routed so everyone has to know the routing table, Interledger allows nodes to maintain simply routing tables for locally known resources, and route other requests elsewhere
Labels: austria, technology, wearedevs, webdevelopment
Friday, August 30, 2013
ViennaJS meetup: Veganizer, Enterprise Software Development, Responsiveview, Web components
- Veganizer: Having fun with image manipulation using canvas and vegetables (including a commercial for filepicker.io) https://github.com/franzenzenhofer/veganizer by @enzenhofer
- Enterprise Software Development for JavaScript refugees – Scala.JS (and not EJBJS 2.0, LOL) @rafacm @sebnozzi
- Responsiveview: http://rv.k94n.com/ https://github.com/k9ordon/responsiveview.
Other tools at http://responsinator.com/ http://lab.maltewassermann.com/viewport-resizer @thisisgordon - Web components: Cool talk by @nikgraf about HTML imports and more. http://www.x-tags.org/ can be used to enable Web components in current browsers already
 Twitter hashtag: #viennajs
Twitter hashtag: #viennajsLabels: javascript, technology, webdevelopment
Tuesday, January 31, 2012
Google Browser Size: Is your content visible?
Then take a look at Google Browser Size, an amazingly simple and effective tool for Web designers to see what percentage of users sees which content, like this:

Of course we all know to place important content towards the top, above the fold, we have seen the heatmaps from eye tracking studies, and we all test at different screen sizes, right? Google Browser Size, already launched back in December 2009, just makes the testing easier and
brings this home with shocking immediacy(Mike Moran at Biznology).
The visualization is based on browser window sizes of people who visit Google, not on actual browser window sizes used when accessing a particular site. Depending on how closely your audience matches the average Google visitor, results may vary.
One caveat: As mentioned on the Browser Size website, the tool works best on web pages with a fixed layout aligned to the left. The visualization can be misleading for liquid or reactive pages that adjust to the available screen width, we well as centered pages.
Labels: google, seo, usability, webdevelopment
Wednesday, November 30, 2011
Velocity Europe 2011 conference report
Web companies, big and small, face the same challenges. Our pages must be fast, our infrastructure must scale up (and down) efficiently, and our sites and services must be reliable … without burning out the team.
Velocity Europe conference Website
 Three years after its inception in California O’Reilly’s Velocity Web Performance and Operations Conference finally made it to Europe. Some 500 people, web developers, architects, system administrators, hackers, designers, artists, got together at Velocity Europe in Berlin on November 8 and 9 to learn about the latest developments in web performance optimization and managing web infrastructure, exchange ideas and meet vendors in the exhibition hall.
Three years after its inception in California O’Reilly’s Velocity Web Performance and Operations Conference finally made it to Europe. Some 500 people, web developers, architects, system administrators, hackers, designers, artists, got together at Velocity Europe in Berlin on November 8 and 9 to learn about the latest developments in web performance optimization and managing web infrastructure, exchange ideas and meet vendors in the exhibition hall.
Velocity Europe was well organized and run. There were power strips everywhere and a dedicated wireless network for the participants, although the latter barely handled the load when everyone was hogging for bandwidth. Seeing bytes trickling in slowly at a performance conference was not without irony. Some things never change: Getting connected sometimes requires patience and endurance. Back in the days I was volunteering at the W3C conferences preparation involved running cables and configuring the “Internet access room”, only then contention for network resources meant waiting for an available computer.
As expected for a techie conference, about the only people wearing jackets and ties were the AV operators, food was plentiful and good, and the sponsors handed out T-shirts, caps, and other give-aways. Plenary sessions were recorded and streamed live, and #velocityconf on Twitter also has a good collection of facts and memorable quotes for those who couldn’t attend in person.

Steve Souders and John Allspaw led through two busy days packed with plenary sessions, lighting talks and two parallel tracks on Web performance and Web operations. While bits and bytes certainly mattered to the speakers and the audience, the focus was clearly on improving the Web experience for users and the business aspects of fast and well-managed Web sites.
The conference started with a controversial talk about building a career in Web operations by Theo Schlossnagle, and I couldn’t agree more with many of his observations, from suggesting discipline and patience (and recommending martial arts to develop those virtues), learning from mistakes, developing with operations in mind to seeing security not as a feature but a mentality, a state of mind. Along the same lines, Jon Jenkins later talked about the importance of dev ops velocity, why it’s important to iterate fast, deploy fast, and learn from mistakes quickly, mentioning the OODA loop. Some of the Amazon.com deployment stats are just mind-boggling: 11.6 seconds mean time between deployments, and over 1,000 deployments in a single hour to thousands of hosts.
Joshua Bixby addressed the relationship between faster mobile sites and business KPIs. Details of the tests conducted and the short-term and long-term effects on visitor behaviour are also available in his recent blog post about a controlled performance degradation experiment conducted by Strangeloop. Another interesting observation was the strong preference of customers for the full Web sites over mobile versions and native apps: One retailer in the U. S. found that of the online revenue growth for that company was driven by the full site. 35% of the visitors on their mobile site clicked through to the full site immediately, 24% left on page 1, another 40% left after page 1, and only 1% bought something.
Performance also matters at Betfair, one of the world’s largest betting providers. Doing cool stuff is important too, but according to Tim Morrow’s performance pyramid of needs that’s not where you start:
- It works.
- It’s fast.
- It’s useful. (I personally have a slight preference for useful over fast.)
- It’s cool.
Jeffrey Veen of Hotwired, Adaptive Path, TypeKit fame kicked off the second day with an inspiring talk on designing for disaster, working through crises and doing the impossible. I liked the fancy status boards on the walls, and the “CODE YELLOW” mode, the openness and the clear roles when something bad happens. And something bad will happen, as John Allspaw pointed out: “You will reach the point of compensation exhausted, systems, networks, staff, and budgets.” A helpful technique for planning changes is to write down the assumptions, expectated outcomes and potential failures individually, and then consolide results as a group and look for discrepancies. If things still go wrong, Michael Brunton-Spall and Lisa van Gelder suggested to stay calm, isolate failing components, and reduce functionality to the core. Having mechanisms in place to easily switch on and off optional features is helpful, down to “page pressing” to produce static copies of the most frequently requested content to handle peak loads.
Several talks covered scripting performance and optimization techniques. Javascript is already getting really fast, as David Mandelin pointed out, running everything from physics engines to an H.264 decoder at 30 fps, as long as we avoid sparse arrays and the slow eval statements and with blocks. Using proven libraries is generally a good idea and results in less code and good cross-browser compatibility, but Aaron Peters made the point that using jQuery (or your favorite JavaScript library) for everything may not be best solution, and accessing the DOM directly when it’s simple and straightforward can be a better choice. Besides that, don’t load scripts if the page doesn’t need them – not that anyone would ever do that, right? – and then do waterfall chart analysis, time and again. Mathias Bynens added various techniques for reducing the number of accesses to the DOM, function calls and lookups with ready-to-use code snippets for common tasks.
For better mobile UI performance, Estelle Weyl suggested inlining CSS and JS on the first page, using data: URLs and extracting and saving resources in LocalStorage. Power Saving Mode (PSM) for Wi-fi and Radio Resource Control (RRC) for cellular are intended to increase battery life but have the potential to degrade perceived application performance as subsequent requests will have to wait for the network reconnection. Jon Jenkins explained the split browser architecture of Amazon Silk, which can use proxy servers on Amazon EC2 for compression, caching and predictive loading to overcome some of these performance hogs.
IBM’s Patrick Mueller showed WEINRE (WEb INspector REmote) for mobile testing, a component of the PhoneGap project.
Google has been a strong advocate for a faster Web experience and long offered tools for measuring and improving performance. The Apache module mod_pagespeed will do much of the heavy lifting to optimize web performance, from inlining small CSS files to compressing images and moving metadata to headers. Andrew Oates also revealed Google’s latest enhancements to Page Speed Online, and gave away the secret parameter to access the new Critical Path Explorer component. Day 2 ended with an awesome talk by Bradley Heilbrun about what it takes to run the platform that serves “funny cat videos and dogs on skateboards”. Bradley had been the first ops guy at YouTube, which once started with five Apache boxes hosted at Rackspace. They have a few more boxes now.
With lots of useful information, real world experiences and ideas we can apply to our Websites, three books signed by the authors and conference chairs, High Performance Web Sites and Even Faster Web Sites, and Web Operations: Keeping the Data On Time, stickers, caps and cars for the kids, Velocity Europe worked great for me. The next Velocity will be held in Santa Clara, California in June next year, and hopefully there will be another Velocity Europe again.
Related links
Photo credit: O´Reilly
Labels: events, javascript, metrics, networking, technology, webdevelopment
Wednesday, February 9, 2011
Google vs. Bing: A technical solution for fair use of clickstream data
 When Google engineers noticed that Bing unexpectedly returned the same result as Google for a misspelling of tarsorrhapy, they concluded that somehow Bing considered Google’s search results for its own ranking. Danny Sullivan ran the story about Bing cheating and copying Google search results last week. (Also read his second article on this subject, Bing: Why Google’s Wrong In Its Accusations.)
When Google engineers noticed that Bing unexpectedly returned the same result as Google for a misspelling of tarsorrhapy, they concluded that somehow Bing considered Google’s search results for its own ranking. Danny Sullivan ran the story about Bing cheating and copying Google search results last week. (Also read his second article on this subject, Bing: Why Google’s Wrong In Its Accusations.)Google decided to create a trap for Bing by returning results for about 100 bogus terms, as Amit Singhal, a Google Fellow who oversees the search engine’s ranking algorithm, explains:
To be clear, the synthetic query had no relationship with the inserted result we chose—the query didn’t appear on the webpage, and there were no links to the webpage with that query phrase. In other words, there was absolutely no reason for any search engine to return that webpage for that synthetic query. You can think of the synthetic queries with inserted results as the search engine equivalent of marked bills in a bank.Running Internet Explorer 8 with the Bing toolbar installed, and the “Suggested Sites” feature of IE8 enabled, Google engineers searched Google for these terms and clicked on the inserted results, and confirmed that a few of these results, including “delhipublicschool40 chdjob”, “hiybbprqag”, “indoswiftjobinproduction”, “jiudgefallon”, “juegosdeben1ogrande”, “mbzrxpgjys” and “ygyuuttuu hjhhiihhhu”, started appearing in Bing a few weeks later:

The experiment showed that Bing uses clickstream data to determine relevant content, a fact that Microsoft’s Harry Shum, Vice President Bing, confirmed:
We use over 1,000 different signals and features in our ranking algorithm. A small piece of that is clickstream data we get from some of our customers, who opt-in to sharing anonymous data as they navigate the web in order to help us improve the experience for all users.These clickstream data include Google search results, more specifically the click-throughs from Google search result pages. Bing considers these for its own results and consequently may show pages which otherwise wouldn’t show in the results at all since they don’t contain the search term, or rank results differently. Relying on a single signal made Bing susceptible to spamming, and algorithms would need to be improved to weed suspicious results out, Shum acknowledged.
As an aside, Google had also experienced in the past how relying too heavily on a few signals allowed individuals to influence the ranking of particular pages for search terms such as “miserable failure”; despite improvements to the ranking algorithm we continue to see successful Google bombs. (John Dozier's book about Google bombing nicely explains how to protect yourself from online defamation.)
The experiment failed to validate if other sources are considered in the clickstream data. Outraged about the findings, Google accused Bing of stealing its data and claimed that “Bing results increasingly look like an incomplete, stale version of Google results—a cheap imitation”.
Whither clickstream data?
Privacy concerns aside—customers installing IE8 and the Bing toolbar, or most other toolbars for that matter, may not fully understand and often not care how their behavior is tracked and shared with vendors—using clickstream data to determine relevant content for search results makes sense. Search engines have long considered click-throughs on their results pages in ranking algorithms, and specialized search engines or site search functions will often expose content that a general purpose search engine crawler hasn’t found yet.Google also collects loads of clickstream data from the Google toolbar and the popular Google Analytics service, but claims that Google does not consider Google Analytics for page ranking.
Using clickstream data from browsers and toolbars to discover additional pages and seeding the crawler with those pages is different from using the referring information to determine relevant results for search terms. Microsoft Research recently published a paper Learning Phrase-Based Spelling Error Models from Clickthrough Data about how to improve the spelling corrections by using click data from “other search engines”. While there is no evidence that the described techniques have been implemented in Bing, “targeting Google deliberately” as Matt Cutts puts it would undoubtedly go beyond fair use of clickstream data.
Google considers the use of clickstream data that contains Google Search URLs plagiarism and doesn't want another search engine to use this data. With Google dominating the search market and handling the vast majority of searches, Bing's inclusion of results from a competitor remains questionable even without targeting, and dropping that signal from the algorithm would be a wise choice.
Should all clickstream data be dropped from the ranking algorithms, or just certain sources? Will the courts decide what constitutes fair use of clickstream data and who “owns” these data, or can we come up with a technical solution?
Robots Exclusion Protocol to the rescue
The Robots Exclusion Protocol provides an effective and scalable mechanism for selecting appropriate sources for resource discovery and ranking. Clickstream data sources and crawlers results have a lot in common. Both provide information about pages for inclusion in the search index, and relevance information in the form of inbound links or referring pages, respectively.| Dimension | Crawler | Clickstream |
|---|---|---|
| Source | Web page | Referring page |
| Target | Link | Followed link |
| Weight | Link count and equity | Click volume |
Following the Robots Exclusion Protocol, search engines only index Web pages which are not blocked in robots.txt, and not marked non-indexable with a robots meta tag. Applying the protocol to clickstream data, search engines should only consider indexable pages in the ranking algorithms, and limit the use of clickstream data to resource discovery when the referring page cannot be indexed.
Search engines will still be able to use clickstream data from sites which allow access to local search results, for example the site search on amazon.com, whereas Google search results are marked as non-indexable in http://www.google.com/robots.txt and therefore excluded.
Clear disclosure how clickstream data are used and a choice to opt-in or opt-out put Web users in control of their clickstream data. Applying the Robots Exclusion Protocol to clickstream data will further allow Web site owners to control third party use of their URL information.
Labels: bing, google, microsoft, seo, technology, webdevelopment
Wednesday, July 28, 2010
July 2010 Vienna JavaScript User Group meeting
 First, Matti Paksula from the University of Helsinki gave a mini-talk about SVG and JavaScript. Matti pointed out that canvas was unsuitable for shapes, “it’s for bitmaps, it’s not accessible, and it doesn’t scale”. Canvas isn’t all bad though; a combination of HTML 5, JavaScript, canvas and SVG is needed to replace Flash. (That probably means that Flash will be around for a while, despite the lack of support from some devices starting with an “i”.)
First, Matti Paksula from the University of Helsinki gave a mini-talk about SVG and JavaScript. Matti pointed out that canvas was unsuitable for shapes, “it’s for bitmaps, it’s not accessible, and it doesn’t scale”. Canvas isn’t all bad though; a combination of HTML 5, JavaScript, canvas and SVG is needed to replace Flash. (That probably means that Flash will be around for a while, despite the lack of support from some devices starting with an “i”.)Demonstrations included the Canvas to SVG conversions and back as shown at SVG Open 2009, and a sneak preview on the latest version which runs completely client-side. Matti also mentioned the PottisJS SVG prototype library and showed an interactive SVG demo.
Next, Roland Schütz talked about JavaScript code management, specifically how to structure code and source files, implement an efficient workflow and automate the building (and testing) of JavaScript code. Roland mentioned a few nice tools for coding and testing JavaScript source code:
- gema general macro processor for pre-processing source files
- JSLint for code quality and consistency checks (for quick tests the online version of JavaScript Lint is quite useful, too)
- phpcpd to detect duplicate code
- Selenium for Web application testing
Finally, Lars Dieckow delivered an impromptu talk entitled “Sommerloch” about–Perl :-). More than fifteen years after the release of Perl 5.000, Perl 6 is just around the corner and the Rakudo Star release will be available from the usual sources starting tomorrow.
As a long time Perl programmer–the first Perl programs I touched were Perl 4 code and I am pretty sure there are some &function calls around still in code we use today–I hadn’t closely followed the development of Perl 6, and it was good to get an update on enhancements and changes in Perl 6 and a live demo of some of the new features after the talk.
Labels: events, javascript, perl, webdevelopment
Monday, May 31, 2010
Blogger on your site
If you are one of the .5% of bloggers who for whatever reason published via FTP or the more secure SFTP, you were left with a choice of moving your blog to blogspot.com or a custom domain name, or moving to another blogging platform. Importing your blog into WordPress is easy, WordPress has some nifty features that Blogger lacks, and you will easily find professionally designed WordPress themes, too, but switching to WordPress means going with the hosted solution on wordpress.com or installing and maintaining WordPress code on your server.
For those who want to stay with Blogger and have Blogger integrated into the Website there are two options, both requiring some hacking and configuration:
- Use the Blogger Data API to retrieve the blog in XML format and perform the rendering locally, most likely by processing the XML with XSLT stylesheets. While very flexible, this means losing the Blogger template capabilities.
- Build a reverse proxy that translates requests for blog resources to the correponding URL on Google's servers. The proxy solution gives flexbility with URL formats and also allows for tweaking the generated HTML code before sending it to the browser.
The Blogger proxy solution
Here is how it works:- Create backup copies of your blog in Blogger and on your server. The migration tool will update all previously published pages with a notice that your blog has moved, so you want to save the state of your blog first.
- Create a secret hostname for your blog in a domain you control, say secretname.example.com, and CNAME this to ghs.google.com. Don't limit your creativity, although the name really doesn't matter much. The migration tool checks that secretname.example.com is CNAMEd to ghs.google.com during the migration.
- Use the Blogger migration tool to move your blog to the new domain. At this point the blog will be up and running at secretname.example.com.
- Install a proxy script on your site which intercepts requests, rewrites the request as needed and sets a Host: secretname.example.com header, sends the modified request to ghs.google.com and rewrites the response to correct absolute links, and optionally tweaks the generated HTML code before sending the response to the browser.

- Configure the Webserver to invoke the script when no local content is available, for example in Apache
RewriteEngine On
RewriteRule ^$ index.html
RewriteCond %{REQUEST_FILENAME} !-f
RewriteCond %{REQUEST_FILENAME} !-d
RewriteRule . /bloggerproxy.php [L] - Google will eventually attempt to index your blog under secretname.example.com. To ensure a consistent appearance of the blog on your site, as the last step point secretname.example.com back to your Webserver and forward requests with that server name to your proxied blog using a 301 redirect.
Disclaimer: This solution is not for the faint of heart. It requires more changes and configuration than simply switching to a custom domain name, and isn't blessed or supported by Google. Use at your own risk.
Labels: google, web2.0, webdevelopment
Monday, August 10, 2009
SEO advice: Redirect wisely
Redirects instruct browsers and search engine crawlers that content is available under a different URL. They often go unnoticed as we access Websites. Along with the new location of the content, the server also sends a response code indicating the type of redirect. From an SEO perspective, you generally care about two response codes, 301 Moved permanently and 302 Found:
- 301 Moved permanently indicates that the resource has been assigned a different URL permanently, and the original URL should no longer be used. What this means for Search engines is that should index the new URL only. Google also transfers full link equity with a 301 redirect, which is the very reason why you will often see the advice to use 301 redirects.
- 302 Found indicates that the originally requested URL is still valid, and should continue to be used. Search engines vary in how they treat 302 redirects and which URL they show in search result pages, but generally will continue to crawl the original URL as recommended in the HTTP/1.1 specification: “The requested resource resides temporarily under a different URI. Since the redirection might be altered on occasion, the client SHOULD continue to use the Request-URI for future requests.”
Choosing the right redirect response code
So which redirect response code should you use? Matt Cutts' description how Google treats on-domain and off-domain 302 redirects covers the basic principles and the heuristics that Google used at the time, which to a large extent still apply.Let's summarize the effects of the two most common redirect status codes again:
- 301 redirects transfer link equity to the new URL.
- 301 redirects remove the original URL from the search index.
- 302 redirects often keep the original URL in the index.
The 301 redirect response is appropriate for the following scenarios:
- Content has moved to a different location permanently, for example to a different server name or a different directory structure of the same server. This may be triggered by the rebranding of content where you want all references to the original content to disappear.
- A Website is accessible under multiple host names, such as example.com and www.example.com, or typo catchers like eggsample.com and example.org, but only one name should be indexed.
- A temporary campaign URL is published in direct mail or print advertising, but the landing page has a different permanent URL that will remain accessible beyond the lifetime of the campaign.
- The requested URL does not match the canonical URL for the resource. Often extraneous session and tracking parameters can be stripped, or path information gets added to help with search rankings, for example http://www.amazon.com/Software-
Development- Principles- Patterns- Practices/dp/0135974445
- The original URL is shorter, prettier, more meaningful, etc. and therefore should show on the search engine results page.
- Temporary session or tracking information gets added to the canonical URL. Those URL parameters should not be indexed since they will not apply to other visitors.
- Multiple load balanced servers deliver the content. Indexing an individual server would defeat the purpose of using load balancing. (There are better ways to load balance than having multiple server names, though.)
The “canonical” meta tag
How can you keep the short URL in the index and still transfer link equity? In summer 2008, we started observing that Google somehow “merged” related URLs and treated them as a single entity, showing identical page rank and identical number of inbound links to all of the URLs.When Google introduced the “canonical” meta tag in February 2009, this suddenly made sense. Once multiple URLs are known to refer to the same page, or a slight variation of a page, the index only needs to keep one instance of the page.
The canonical meta tag helps the webmaster of a site who give search engines a hint about the preferred URL. The canonical meta tag also helps search engines since mapping multiple crawled URLs to the same page and indexing it only once just became easier.
Whether link equity fully transfers between multiple URLs mapped to the same page remains to be seen. At least within the same domain, this unification process may allow keeping the vanity URL in the index with a 302 redirect response while still transferring link equity.
PS. For an excellent and detailed description how redirects work, how to configure your Web server and what each status code does, see Sebstian's pamphlet The anatomy of a server sided redirect: 301, 302 and 307 illuminated SEO wise.
Labels: networking, seo, webdevelopment
Wednesday, June 24, 2009
Disagreeing with Jakob Nielsen on security—Password masking makes logins more secure
Disagreeing with Jakob Nielsen on security is easier, especially when he advocates to remove password masking as a means to improve usability and claims that this doesn't lower security.
While not offering a high degree of protection, the password masking does a pretty good job for most situations. Certainly, a determined and skilled criminal would be able to observe which keys are pressed, or use other attack vectors to intercept my Web interactions. I am often surrounded by trustworthy people who still shouldn't know my passwords, don't care about my passwords and even politely turn their eyes away while I am logging in. Whether showing someone a Website or doing a demo to a larger audience, accessing protected areas of a site in a semi-public environment like a desk-sharing area at work or logging in from a mobile device, those little stars or dots protect my passwords well from becoming exposed.
Security and usability should not be conflicting objectives; in fact usability is an important aspect for any security system, or users will work around usability issues and use it in unintended ways, like copying and pasting passwords from a text file as Nielsen mentions. An extra checkbox to enable password masking just adds complexity to the user interface and may confuse users more than not being able to see their password.
Typing passwords on mobile devices (or foreign keyboards, for that matter) can be challenging. Some smartphones like the iPhone or the Nokia N95 show the letter as typed but then quickly replacing it with an asterisk, which is a reasonable compromise.
Instead of cluttering Web forms with additional checkboxes, web developers should demand that browsers and mobile devices provide an option to remove password masking when desired by the user. This would maintain the current level of security by not exposing the passwords to people looking over users' shoulders and address the usability issue for those who have difficulty typing their password and would benefit from visual feedback.
Until then, use this JavaScript bookmarklet to unmask password fields as needed:
for(var i=0;(var a=document.getElementsByTagName("input")[i]);i++){
if(a.getAttribute("type").indexOf("password")!=-1){
a.type="text"
}
}
window.focus();
(all on one line, or simply drag the Unmask passwords bookmarklet link to your bookmarks).
PS. More ways to reveal passwords in a controlled manner can be found in Martin Brinkmann's blog post Reveal your saved Passwords in Firefox.
Labels: technology, usability, webdevelopment
Saturday, May 30, 2009
IE6 DOM weirdness: It was the base and not the comma
Fortunately I had just received a new ThinkPad (more about that later) and hadn't upgraded Internet Explorer yet. Testing with IE6, my code failed miserably. Debugging with the indispensable FireBug light tool revealed that a shared library function for accessing meta information didn't return any information. The very same library function was working nicely on the production Web site, though; at least we hadn't heard any complaints, which given the percentage of users accessing our Web site with IE6 was highly unlikely.
Staring at the screen in disbelieve, our resident jQuery guru eventually found the culprit. Unlike with the infamous Undefined is null or not an object problem, it was not an issue with an extra comma this time.
Rather, IE6 seems to get the structure of documents containing a
base tag wrong, making subsequent meta and link elements children of the base element, turning this source
into this DOM tree:
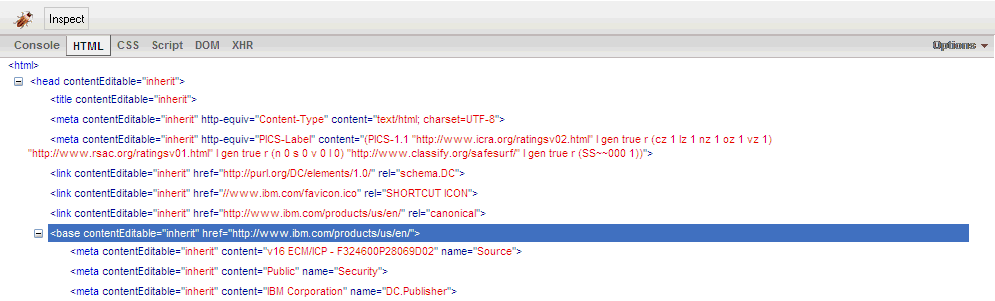
So the selector which was correctly looking for
html > meta would fail in the rare presence of a base tag, such as on a test page created by yours truly. The quick fix was a slightly less efficient selector html meta, and we were once again painfully reminded that IE6 tends to behave differently from current browsers and requires separate testing.Related information:
- Justin Rogers, BASE tag changes in IE 7 with Examples
Labels: javascript, webdevelopment, windows
Wednesday, September 3, 2008
Google Chrome first impressions
But then of course it's hard to ignore a new browser when it's launched by Google. Matt Cutts quickly blogged about the Google Chrome announcement and conspiracy theories, and the search engine guessing feature in particular caught my interest.
www.ibm.com has supported OpenSearch for years and it's good to see a browser finally making good use of the OpenSearch description and providing access to custom search engines using keyboard navigation. With the OpenSearch definition for IBM Search enabled, typing ibm.com Green IT selects IBM Search as the preferred engine for that search:
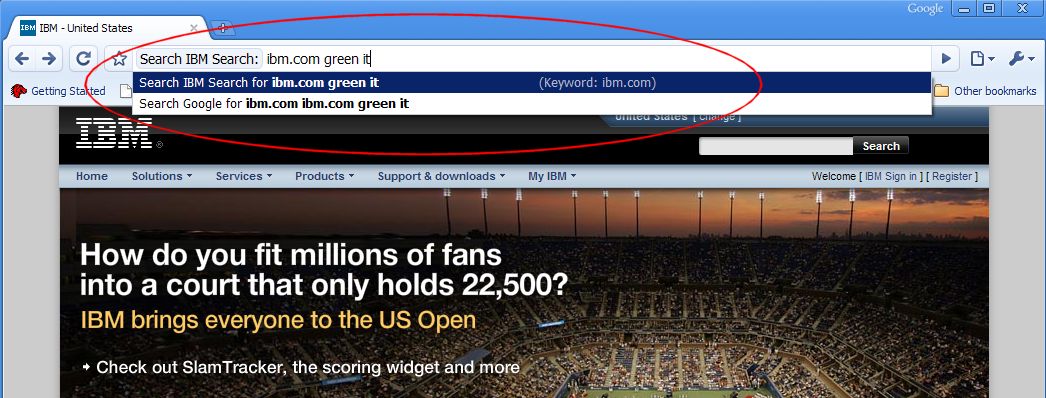
The same can be achieved in Firefox with keywords, albeit not as easily.
Rendering of XML content including RSS news feeds leaves much to be desired. Hopefully Google will add full XML rendering support and integrate a feed reader soon.
Incognito browsing is another neat idea, it won't help much to preserve your privacy but could be useful for testing when you don't want all the test pages to clutter your browser history.
One prerequisite for me using Chrome is support by RoboForm which keeps track of all my accounts and passwords. RoboForm does not work with Safari but hopefully with Chrome being open source will support this browser. Web development tools that work with Chrome will be the other deal breaker.
In the meantime I will continue to experiment with Chrome and see what else Google's latest brainchild has to offer.
Labels: technology, webdevelopment
Thursday, August 14, 2008
'undefined' is null or not an object
This script worked perfectly fine in Firefox, in Seamonkey, even in Opera but failed miserably in Internet Explorer with the not so helpful error message 'undefined' is null or not an object:
var items = [
{id: 'type', condition: !document.referrer},
{id: 'link', condition: !!document.referrer},
];
for (var i=0; i < items.length; i++) {
var item = items[i];
if(typeof(item.condition) == 'undefined' || item.condition) { // Bang!
// do something useful
}
Can you see the problem (and why this works in Mozilla)?
Labels: javascript, webdevelopment
Friday, June 20, 2008
Firefox 3

While I consider raw traffic numbers only mildly useful and the hunt for traffic records somewhat old-fashioned (when IBM did run the Olympics Websites we would report record traffic numbers, and with the technology available back then the numbers were impressive, but that was in the 1990ies) I gladly did my part to set the world record. I mean, how often do you get a chance to be part of a world record, even if your contribution is only 1/8290545.
I even installed Firefox 3 :-) and for most parts have been satisfied with the result. The only complaint I have is that the installation overwrote the previously installed Firefox 2 despite placing the new version in a different directory, and sure enough some extensions were considered incompatible and therefore disabled.
Multiple Internet Explorer versions can coexist on the same machine thanks to the wonderful Multiple IE installer, can we please get an easy and automated way to run multiple versions of Firefox without fiddling with profiles?
Labels: technology, webdevelopment, windows